Russian tech giant Yandex, in collaboration with Oxford and Cambridge Universities, recently launched the Shifts Challenge at the annual NeurIPS conference, designed to tackle the problem of distributional shift in machine learning (ML). This research is essential to ensure ML models, used in things like autonomous vehicles, can operate effectively in any situation, even those they have never previously encountered.
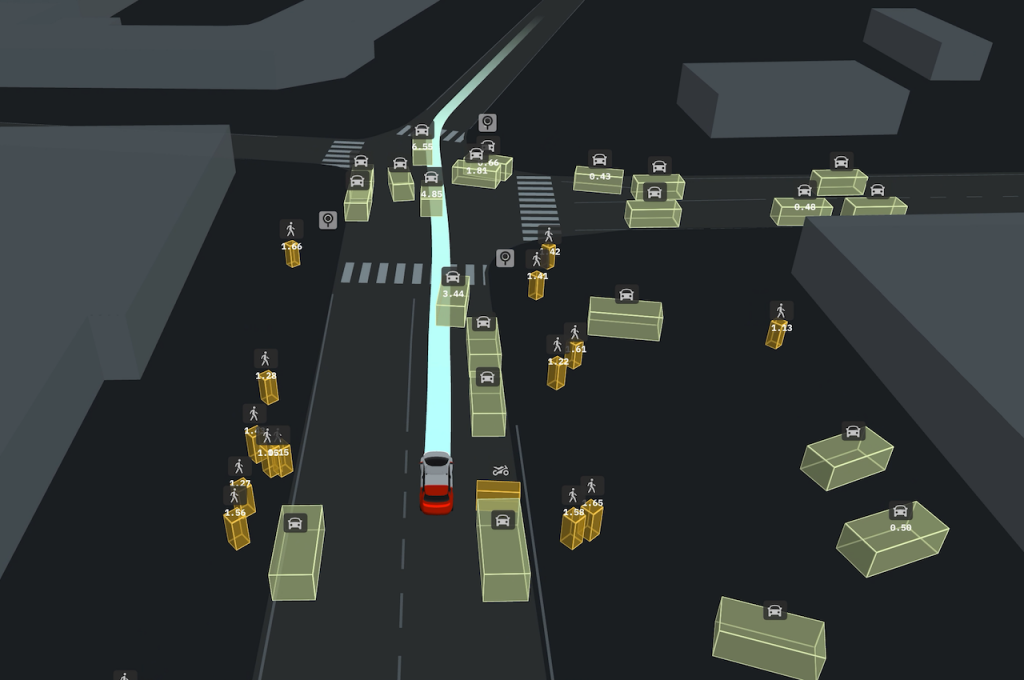
The competition was divided into three tracks – weather, machine translation and autonomous vehicles. The autonomous vehicle track featured a record-breaking dataset — the largest in the industry to date — containing 600,000 scenes or more than 1,600 hours of driving.
We spoke to Dr. Andrey Malinin, Senior Research Scientist at Yandex, to find out more about this challenge and the implications it has for the wider development of artificial intelligence and ML technology.
1. Before we dig into the challenge itself, let’s talk about the dataset. Yandex has released the largest autonomous vehicle (AV) dataset in the industry to date as part of this competition – where did that data come from?

Yandex Self-driving Group (Yandex SDG) tests its AV technology in six cities located in the United States, Israel and Russia, and has collected data through all types of weather conditions. We’ve chosen to release a rather large and diverse subset of this data that includes 600,000 scenes, or more than 1,600 hours of driving.
This dataset features tracks of cars and pedestrians in the vicinity of the vehicle, including parameters like location coordinates, velocity, acceleration and more. However, the dataset does not contain images showing personal information such as license plates or images of pedestrians. By releasing such a comprehensive real-life dataset with detailed annotation to researchers and developers all around the world, we aim to accelerate the global development of safe and reliable AV technology.
2. Why did you choose to focus on the problem of distributional shift?
Distributional shift, or the mismatch between training and deployment data, is ubiquitous in Machine Learning. In real applications, the deployment data seldom fully matches the training data, and can even evolve over time. This mismatch can cause a degradation in model performance, especially when the degree of shift is large. This is especially important to be aware of in applications with strict safety requirements, such as AV technology.
Ideally, we would like to produce reliable, robust models which generalize well to changing situations. This is incredibly challenging. Thus, it is also important for these models to “know when they don’t know”, to prevent bad decisions. Models should produce estimates of uncertainty which correlate to the degree of confidence in their prediction. Solving these tasks is necessary to produce safe, reliable and scalable AI systems. On a more philosophical note, being able to both generalize broadly to novel situations and understand the limits of one’s knowledge is a fundamental requirement for artificial general intelligence (AGI).
3. The challenge tracks are weather, machine translation, and vehicle motion prediction. Why those three areas of focus?
Most research in the area of robustness to distributional shift and uncertainty estimation has been done on small image classification datasets, such as CIFAR10/CIFAR100, with synthetic distributional shift. We wanted to examine the problem of distributional shift more broadly — both at a larger scale, across different tasks and modalities and with examples of distributional shift from the real world. Fortunately, the Yandex weather and translation services, as well as the Self-Driving Group, were happy to provide such data. Each of the datasets we have provided covers a very different data modality and task types and presents unique challenges and opportunities for research.
Weather prediction is a regression task on heterogeneous tabular data, where distributional shift occurs both in time and climate. This is representative of the challenges found in applications with strict safety and reliability requirements, like medicine and finance, where data comes from different sources, has non-uniform coverage of all population grounds, contains missing values, is represented in tabular form and often goes “stale” over time.
Machine translation is a discrete sequence prediction task on text data. Here, shift occurs in terms of language style and use — systems are often trained on formal, grammatically correct language, but may encounter informal language that contains emojis, punctuation and grammatical errors, slang, etc. Ideally, translation systems should perform equally well on all data, but in practice they may perform worse when encountering atypical language. Furthermore, uncertainty estimation for discrete sequence prediction tasks is highly non-trivial and has been seldom examined by the ML community. All this means that this is a fruitful area for further investigation.
Finally, vehicle motion prediction is a continuous sequence prediction task using both static and dynamic HD maps and telemetry. Here, distributional shift occurs in location, season, precipitation and time of day. Motion prediction is one of the most important problems in the autonomous driving domain, which naturally has high safety requirements. A self-driving vehicle, like any vehicle, needs a certain amount of time to change its speed, and sudden changes in speed and acceleration may be uncomfortable or even dangerous for passengers. To ensure a safe and comfortable ride, the motion planning module must predict where other vehicles might end up in a few seconds. The problem is complicated because it involves inherent uncertainty, which must be precisely quantified in order for the planning module to make the right decision.
4. Is there anything special in how the entries are evaluated?
One of the novelties of our challenge is that we *jointly* evaluate uncertainty estimation and robustness to distributional shift. Previously, the two were evaluated separately — robustness via accuracy on shifted data and uncertainty via anomaly detection metrics. However, this assumes that we have “matched data” on which models work well and shifted data, on which models work poorly. Real life is more complex — there may be under-represented matched data on which models work poorly and shifted data on which the models successfully generalize. We don’t care whether data has come from the matched or shifted dataset, only whether the model performs well on this data.
Thus, we need an evaluation paradigm which captures this. In this challenge we use evaluation datasets containing both matched and shifted data on which we want models to both have low error overall and be able to indicate errorful predictions via estimates of uncertainty. These uncertainties can be used to further reduce error by highlighting and replacing the most errorful predictions with “oracle” predictions. This assumes a scenario where a model can ask for human intervention in difficult situations. Models with better uncertainty estimates can lower their error further than ones which have poor estimates.
5. How do you hope the results of this challenge will translate into real-world innovation?
We hope that this challenge will stimulate innovation in a few ways.
Firstly, the main obstacle to the development of robust models which yield accurate uncertainty estimates is lack of availability of large, diverse datasets which contain examples of distributional shift from a range of real, industrial tasks. Most research in the area has been done on small image classification datasets with synthetic distributional shift. Unfortunately, promising results on these datasets don’t always generalize to large-scale industrial applications. By releasing a large dataset with examples of real distributional shift on a diverse set of tasks, we are enabling researchers to validate their work and develop better solutions. Moreover, we hope that this work will set the new standard for evaluation in uncertainty estimation and robustness research.
Secondly, we hope that by examining a wider range of tasks, we will develop deeper fundamental insights into the problems of distributional shift and uncertainty estimation.
Last but not least is that uncertainty estimation and robustness have been, until recently, relatively niche fields. We hope that this challenge will attract further attention to this field from the broader ML community, allowing efforts to be dedicated to solving these problems.


